-
Machine-LearningAI & Research/Deep Dive : Theory 2024. 2. 19. 13:47
AI-tech-interview를 위한 머신러닝 파트입니다.
전체적인 내용과 질문은
https://github.com/boost-devs/ai-tech-interview/blob/main/answers/2-machine-learning.md 해당 사이트를 참고했습니다.
#1
알고 있는 metric에 대해 설명해주세요. (ex. RMSE, MAE< recall, precision ..)
평가지표(mteric) -> 분류를 위한 평가지표 vs 회귀를 위한 평가지표
분류 작업에 적용할 수 있는 평가지표
- 정확도(accuracy)
정확도는 모델의 예측이 얼마나 정확한지를 의미한다. 예측 결과가 동일한 데이터 개수 / 전체 예측 데이터 개수로 계산 가능, 해당 방법은 그냥 맞춘거/전체 데이터 이렇게 생각하면 될듯. 근데 이때 문제가 데이터 불균형, 라벨링 불균형 문제가 있음. 예를 들어 0과 1 비율이 9:1 처럼 무너져 잇는 경우 모두 0으로 예측하면 정확도가 90프로가 나온다. 따라서 다른 지표 사용 필요함
- 오차 행렬(confusion matrix)
오차 행렬은 모델이 예측을 하면서 얼마나 헷갈리고 있는지를 보여주는 지표. 주로 이진 분류에서 사용됨
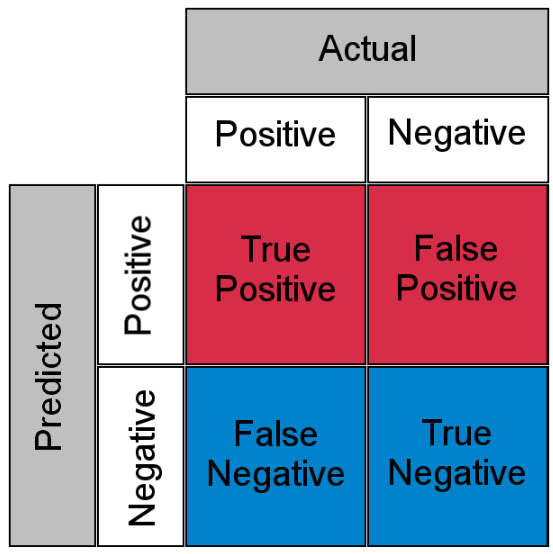
위의 그림을 참고하면 하나를 예를 들면 True Positive는 모델은 positive라고 예측했는데 실제로도 positive인 경우이다.
위의 값들을 바탕으로 모델이 어떤 오류를 발생시켰는지를 살펴볼 수 있다.
정확도는 (TN+TP) / (TN + FP + FN + TP)로 계산
- 정밀도(precision), 재현율(recall)
정밀도와 재현율은 긍정 데이터 예측 성능에 초점을 맞춘 평가지표이다.
정밀도 : 예측을 positive로 한 데이터 중 실제 positive인 비율 -> TP / (FP + TP)
재현율 : 실제 positive 데이터 중 positive로 예측한 비율 -> TP / (FN + TP)
정밀도와 재현율은 trade-off 관계를 갖는다. 정밀도는 FP, 재현율은 FN을 낮춤으로써 positive 예측의 성능을 높인다. 가장 좋은 경우는 두 지표 다 적절하게 높은 경우, 하나의 치중하는건 좋지 않다.
- F1-Score
정밀도와 재현율 한 쪽에 치우치지 않고 둘다 균형을 이루는 score, 정밀도와 재현율의 조화평균으로 계산함
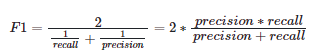
- ROC-AUC
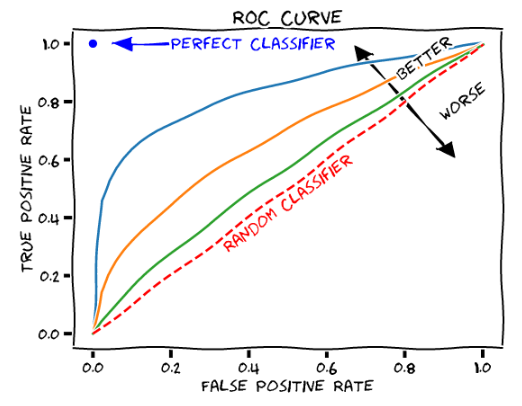
ROC는 FPR(False Positive Rate)가 변할 때 TPR(True Positive Rate)가 어떻게 변하는지를 나타내는 곡선을 말한다. 여기서 FPR이란 FP / (FP + TN)이고, TPR은 TP / (FN + TP)으로 재현율을 말한다. FPR을 움직이는 방법은 분류를 결정하는 임계값을 변경함으로써 가능하다. 예를 들어 FPR이 0이 되려면 임계값을 1로 설정하면 된다. 이렇게 하면 임계값이 높다 -> positive 기준이 높다 -> 모두 False로 예측한다. 이렇게 임계값을 움직이면서 나오는 FPR과 TPR을 각각 x와 y좌표로 두고 그린 곡선이 ROC이다.
AUC는 ROC 곡선의 넓이를 말한다. AUC가 높을수록 그래프가 왼쪽 위로 휘어진다. 이는 TPR이 높고 FPR이 낮을 때 성능이 좋다. -> 예측 오류가 낮아지기 때문
회귀 작업에 적용할 수 있는 평가지표
MAE(Mean Absolute Error)는 예측값과 정답값 사이의 차이의 절대값의 평균

MSE(Mean Squared Error)는 예측값과 정답값 사이의 차이의 제곱의 평균, 여기서 주의할 점은 MAE와 달리 제곱을 했기 때문에 이상치에 민감할 수 있음

RMSE(Root Mean Squared Error)는 MSE에 루트를 씌운 값

RMSLE(Root Mean Squared Logarithmic Error)는 RMSE와 비슷하나 예측값과 정답값에 각각 로그를 씌워 계산
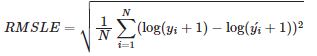
R Squared는 분산을 기반으로 예측 성능을 평가하는 지표를 말한다. 결정계수, 흔히 R 제곱이라고 불리는 것이고 회귀 모델에서 독립변수가 종록변수를 얼마만큼 설명해 주는지를 가리키는 지표이다. 독립변수의 수가 증가하면 계수의 값이 상승한다. 정답값의 분산 대비 예측값의 분산 비율을 지표로 하며, 1에 가까울수록 정확도가 높다.
#2
정규화를 왜 해야할까요? 정규화의 방법은 무엇이 있나요?
정규화는 개별 피처의 크기를 모두 똑같은 단위로 변경하는 것이다. 정규화를 하는 이유는? -> 피처의 스케일이 심하게 차이가 나는 경우 값이 큰 피처가 더 중요하게 여겨질 수 있기 때문이다.이를 막기 위해 피처 모두 동일한 스케일로 반영되도록 하는 것이 정규화의 개념이다.
실제로 산학 과제를 진행하면서 현대 모비스 과제는 괜찮았는데 두산 과제에서 scale의 문제가 있어 min-max normalization 아이디어 같이 penlaty loss를 적용했던 기억이 있다.
정규화 방법은 대표적으로
1. 최소-최대 정규화(min-max normalization)
- 각 피처의 최소값을 0, 최대값을 1로 두고 변환하는 방법이다. 값을 x로, 최소값을 min, 최대값을 max로 둘 때, 정규화 된 값은 x-min / max -min 으로 계산할 수 있다.
2. Z-점수 정규화(z-score normalization)
- 각 피처의 표준편차와 평군값으로 정규화시킨다. 정규화된 값은 x-mean / std로 계산 가능
#3
Local Minima와 Global Minimum에 대해 설명해주세요.
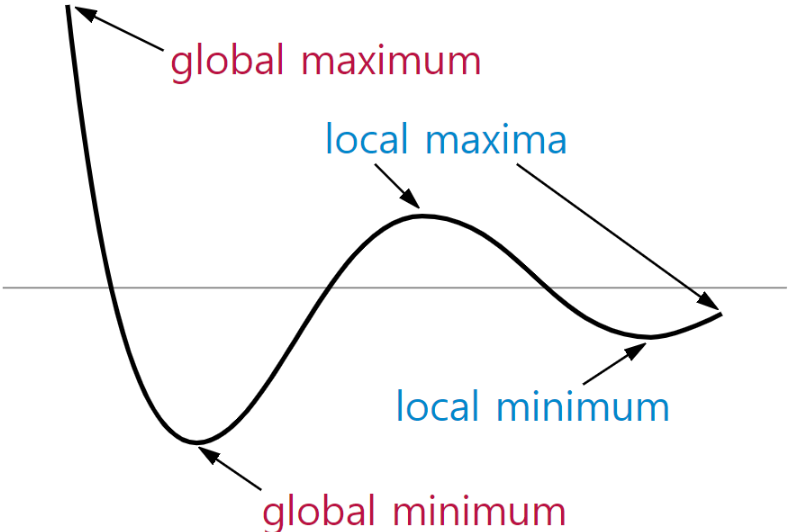
Gradient desecent 알고리즘에서 볼 수 있는 개념이다. cost function에서의 Global Minimum은 에러가 최소화되는 즉, 우리가 찾고자 하는 지점을 말하며(일종의 전체에서 가장 minimum, maximum한 부분) Local Minima는 에러가 최소가 될 수 있는 후보가 되는 지점 중 Global minimum을 뺀 나머지 부분을 얘기함. 학습을 하다 보면 local minimum에 빠지거나 해당 minimum이 global minimum이라고 생각할 수 있다. 이를 해결하기 위해 optimization이 필요한거고 모멘텀이나 같은 최적화 알고리즘을 사용하거나 learning rate를 조절하는 부분도 local minima에 빠지지 않게 하는 방법 중 하나이다.
#4
차원의 저주에 대해 설명해주세요.
예전에 다크프로그래머 보면서 공부했던 내용인데...또 까먹..
차원의 저주란 데이터 차원이 증가할수록 해당 공간의 크기가 기하급수적으로 증가하여 데이터 간 거리가 기하급수적으로 멀어지고 희소한 구조를 갖게 되는 현상을 말한다. 문제 계산 법이 지수적으로 커짐 -> 빈공간이 증가하는 공간의 성김 현상을 보인다.
-> Feature가 많아질수록, 동일한 데이터를 설명하는 빈 공간이 증가하고 알고리즘 모델링 과정에서 저장 공간과 처리 시간이 불필요하게 증가됨(성능 저하)
해결하는 방법은 차원을 증가시킨만큼 더 많은 데이터를 추가하거나 PCA, LDA< LLE, MDS와 같은 차원 축소 알고리즘으로 차원을 줄여 해결 -> 자세한 알고리즘 설명은 뒤에
#5
dimension reduction 기법으로 보통 어떤 것들이 있나요?
차원 축소는 피처 선택(feature selection)과 피처 추출(feature extraction)으로 나눌 수 있다. 우선 피처 선택은 특정 피처에 종속성이 강한 불필요한 피처는 제거하고 데이터의 특징을 잘 표현하는 주요 피처만 선택하는 것을 말한다. 반면 피처 추출은 기존 피처를 저차원의 피처로 압축하여, 피처를 함축적으로 잘 설명할 수 있도록 저차원으로 매핑하는 것을 말한다. 대표적인 피처 추출 알고리즘으로 PCA, SVD, NMF, LDA 등이 있다. 보통은 피처 추출을 많이 하지 않나?(개인적인 생각)
#6
PCA는 차원 축소 기법이면서, 데이터 압축 기법이기도 하고, 노이즈 제거기법이기도 합니다. 왜 그런지 설명해주실 수 있나요?
PCA(Principle Component Analysis)는 입력 데이터의 공분산 행렬을 기반으로 고유벡터를 생성하고 이렇게 구한 고유 벡터에 입력 데이터를 선형 변환하여 차원을 축소하는 방법이다. 차원은 곧 입력 데이터의 피처를 뜻하므로 데이터 압축 기법으로 볼 수도 있다. 데이터의 피처 중 차원은 하나일 수 있으니까, 일종의 데이터 압축 기법이기도 함.
또한 PCA는 고유값이 가장 큰, 즉 데이터의 분산이 가장 큰 순으로 주성분 벡터를 추출하는데, 가장 나중에 뽑힌 벡터보다 가장 먼저 뽑힌 벡터가 데이터를 더 잘 설명할 수 있기 때문에 노이즈 제거 기법이라고도 불린다. 일종의 이 과정이 노이즈를 제거하는 과정이라고 생각 할 수 있음.
고유값이 크다 -> 데이터의 분산이 크다 -> 중요한 feature일 가능성이 있다. -> 먼저 뽑는다 (주성분 벡터) : 중요한 것을 뽑는다 = 중요하지 않은 것(노이즈)를 제외한다.
#7
LSA, LDA, SVD 등의 약자들이 어떤 뜻이고 서로 어떤 관계를 가지는지 설명할 수 있나요?
PCA는 Principle Component Analysis의 약자로 데이터의 공분산 행렬을 기반으로 고유벡터를 생성하고 이렇게 구한 고유 벡터에 입력 데이터를 선형 변환하여 차원을 축소하는 방법이다. SVD는 Singular Value Decomposition의 약자로 PCA와 유사한 행렬 분해 기법을 사용하나 정방 행렬(square matrix)를 분해하는 PCA와 달리 행과 열의 크기가 다른 행렬에도 적용할 수 있다. 해당 내용은 뒤에 수학 파트에서 더 자세히 공부하자.
LSA는 Latent Semantic Analysis의 약자로 잠재 의미 분석을 말하며, 주로 토픽 모델링에 자주 사용되는 기법이다. LSA는 DTM(Document-Term Matrix)이나 TF-IDF(Term Frequency-Inverse Document Frequency) 행렬에 Truncated SVD를 적용하여 차원을 축소시키고, 단어들의 잠재적인 의미를 이끌어낸다. Truncated SVD는 SVD와 똑같으나 상위 n개의 특이값만 사용하는 축소 방법이다. 이 방법을 쓸 경우 원 행렬로 복원할 수 없다.
LDA는 Latent Dirichlet Allocation 혹은 Linear Discriminant Analysis의 약자이다. 전자는 토픽모델링에 사용되는 기법 중 하나로 LSA와는 달리 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추정하는 기법을 말한다. 후자는 차원축소기법 중 하나로 분류하기 쉽도록 클래스 간 분산을 최대화하고 클래스 내부의 분산은 최소화하는 방식을 말한다.
LDA는 왜 처음 들어봤지? 자연어 처리 쪽이구나... 하이퍼커넥트 생각나네.. 이 부분도 살펴보면 좋을듯
19-01 잠재 의미 분석(Latent Semantic Analysis, LSA)
LSA는 정확히는 토픽 모델링을 위해 최적화 된 알고리즘은 아니지만, 토픽 모델링이라는 분야에 아이디어를 제공한 알고리즘이라고 볼 수 있습니다. 이에 토픽 모델링 알고리즘인 LD…
wikidocs.net
19-02 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
토픽 모델링은 문서의 집합에서 토픽을 찾아내는 프로세스를 말합니다. 이는 검색 엔진, 고객 민원 시스템 등과 같이 문서의 주제를 알아내는 일이 중요한 곳에서 사용됩니다. 잠재 디…
wikidocs.net
04-03 문서 단어 행렬(Document-Term Matrix, DTM)
서로 다른 문서들의 BoW들을 결합한 표현 방법인 문서 단어 행렬(Document-Term Matrix, DTM) 표현 방법을 배워보겠습니다. 이하 DTM이라고 명명합니다. 행과…
wikidocs.net
04-04 TF-IDF(Term Frequency-Inverse Document Frequency)
이번에는 DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치에 대해서 알아보겠습니다. TF-IDF를 사용하면, 기존의 DTM을 사용하는 것보다 보다 많…
wikidocs.net
해당 부분은 내가 NLP 쪽을 혹시나 인터뷰 할 일이 있으면 참고하자.
'AI & Research > Deep Dive : Theory' 카테고리의 다른 글
Textual dataset distillation via language model embedding (0) 2026.03.03 Spectral Clustering (0) 2022.08.12 정보 이론 개념 Study (0) 2022.05.17 Knowledge distillation (0) 2022.02.06 Lab-02 ~ 05 (0) 2021.01.30