-
Amazon Bedrock Model DistillationDev & Carrer/Cloud & AWS Architecture 2026. 3. 1. 00:52
Knowledge Distillation 기초부터 응용까지
위 글이랑 이어지는 내용입니다.
지금까지 우리는 Model Distillation의 개념과 다양한 사용 사례에 대해 살펴보았으며, 이를 Fine-tuning과 비교하여 설명했습니다. 이제 이론적 배경에서 한 걸음 더 나아가, Amazon에서 제공하는 Bedrock 플랫폼에서 Model Distillation을 어떻게 활용할 수 있는지 그 구체적인 방법과 절차에 대해 상세히 설명하도록 하겠습니다.

Amazon Bedrock의 Model Distillation은 교사 모델에서 학생 모델로의 지식 전달 과정을 자동화합니다. 이 과정은 합성 데이터 생성, 학생 모델 훈련 및 평가, 최종 모델 호스팅을 포함합니다. Bedrock은 다양한 데이터 합성 방법을 활용하여 특정 사용 사례에 최적화된 경량 모델을 만듭니다. 예를 들어, 유사 프롬프트 생성으로 훈련 데이터를 확장하거나, 고객 제공 프롬프트-응답 쌍을 기반으로 고품질 합성 응답을 생성할 수 있습니다. 이를 통해 고급 모델에 근접한 성능의 증류된 모델을 효율적으로 만들 수 있습니다.
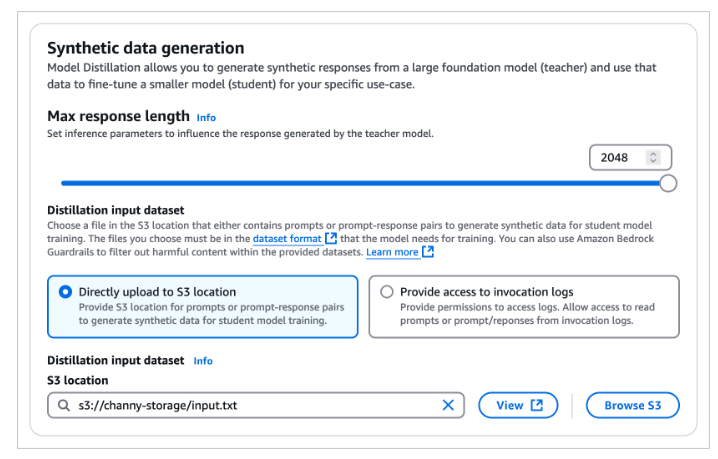
합성 데이터를 생성하려면 교사 모델에서 생성된 응답을 결정하는 최대 응답 길이의 값을 설정합니다. S3 버킷에 있는 증류 입력 데이터 세트를 선택하고 해당 데이터세트는 사용 사례에 대한 프롬프트를 나타냅니다. 입력 데이터 세트 준비에 대해 부연 설명을 더하자면, 옵션이 두가지가 있습니다.


옵션 1: 나만의 프롬프트 제공
프롬프트를 수집하여 JSON Line(JSONL) 형식으로 저장합니다.
위와 같은 구조를 사용해야 합니다. schemaVersion구조에는 값이 있어야 하는 필수 필드가 포함되어야 합니다 bedrock-conversion-2024. 모델에 할당된 역할을 나타내는 시스템 프롬프트를 선택적으로 포함할 수 있습니다. 메시지 필드에서 사용자 역할은 모델에 제공된 입력 프롬프트를 포함하는 필수이고, 원하는 응답을 포함하는 보조 역할은 선택 사항입니다.TIP: 입력 데이터셋을 준비할 때는 위 그림에 제시된 JSON 형식을 참고하여 JSONL 파일을 생성해야 합니다. 최소 데이터셋 요구사항으로, 100개 이상의 JSON 객체가 필요하며 각 객체는 예시와 동일한 구조를 따라야 합니다. 이렇게 생성된 JSONL 파일이 Input 데이터셋으로 사용됩니다.


옵션 2: 호출 로그 사용
모델 증류에 호출 로그를 사용하려면 모델 호출 로깅을 켜고 모델 호출 작업 중 하나를 사용하고 로그의 대상으로 S3 버킷을 설정합니다. 이 옵션을 사용하면 Amazon Bedrock에서 프롬프트만 사용할지, 아니면 로그 호출 로그의 프롬프트-응답 쌍을 사용할지 지정할 수 있습니다. 프롬프트만 사용하려는 경우 교사 모델에서 다양하고 더 높은 품질의 응답을 생성하기 위해 독점적인 데이터 합성 기술을 추가할 수 있습니다.Amazon Bedrock에 최대 15K개의 프롬프트 또는 프롬프트-응답 쌍을 제공하여 학생 모델을 미세 조정할 수 있습니다. 학생 모델이 귀하의 특정 요구 사항을 충족하도록 미세 조정되었는지 확인하려면 다음을 적극 권장합니다.
Amazon Bedrock에서 프롬프트만 사용하려면 모든 모델에서 최소 100개의 프롬프트-응답 쌍이 생성되어야 합니다.
Amazon Bedrock에서 호출 로그의 응답을 사용하려면 호출 로그의 모델에서 생성된 프롬프트-응답 쌍이 최소 100개 있어야 하며, 이는 선택한 교사 모델과 정확히 일치해야 합니다.
어렵게 설명했지만 간단합니다. 모델 증류를 위해서는 프롬프트-응답 쌍이 필요하고 둘다 있으면 기존의 데이터를 위 JSON 양식에 맞게 구성하고 JSONL 파일을 S3에 업로드해서 사용하면 됩니다. 또한 이전의 모델 호출 로그가 있을 경우 해당 로그를 사용하고 싶으면 옵션 2로 로그의 대상으로 S3 버킷으로 대상하고 프롬프트에 대한 응답이 없을 경우 프롬프트를 이용해 Amazon Bedrock에서 생성한 응답을 활용합니다. 이때 당연히 추론 호출에 대한 추가 요금이 부과됩니다.그런 다음 Amazon S3 위치를 설정한 후 Distillation 출력 메트릭 데이터와 사용자를 대신하여 Amazon S3에 쓸 수 있는 권한을 저장하기 위해 Distillation 작업 생성을 선택합니다. 이때 서비스 역할에 Bedrock과 S3에 대한 권한이 존재해야 합니다.

- 로그를 전달할 S3 버킷을 생성합니다.
- 아래와 같이 버킷 정책을 추가합니다(선택적으로 accountId, region, bucketName, 의 값을 바꿉니다 prefix).
- S3 버킷에 위 정책을 적용

프로덕션 데이터를 증류에 재사용하고 교사 응답을 다시 생성하지 않으려면 모델 호출 로깅을 켜서 Amazon Bedrock에서 사용되는 AWS 계정의 모든 호출에 대한 호출 로그, 모델 입력 데이터 및 모델 출력 데이터를 수집합니다. 요청 메타데이터를 추가하면 나중에 호출 로그를 쉽게 필터링할 수 있습니다.
추가로, Amazon Science와 Microsoft의 Knowledge Distillation 논문에 대해 간단히 설명하도록 하겠습니다.
Knowledge distillation method for better vision-language models
트랜스포머 기반 대규모 모델들은 뛰어난 성능을 보이지만 실시간 사용에 너무 느리다는 문제가 있습니다. 이를 해결하기 위해 지식 증류 기법이 사용되는데, 기존에는 교사 모델(큰 모델)과 학생 모델(작은 모델)의 어텐션 헤드를 1:1로 정렬하는 방식이 주로 사용되었습니다.
본 연구에서는 새로운 접근 방식을 제안했습니다.
- 교사 모델의 모든 어텐션 헤드 지식을 학생 모델의 모든 어텐션 헤드로 증류합니다.
- -> 이를 통해 학생 모델의 단일 어텐션 헤드가 교사 모델의 여러 어텐션 헤드 정보를 효과적으로 인코딩할 수 있게 됩니다.

일반적으로 시각 언어 모델은 각 모달리티(시각, 텍스트 등)에 대해 별도로 사전 학습된 하위 모듈을 갖추고, 전체 네트워크가 멀티모달 표현을 학습하도록 추가 사전 학습이 진행됩니다. 이후 특정 작업에 맞게 미세 조정됩니다.
기존의 지식 증류 방법에서는:
- 교사-학생 모델 간 어텐션 헤드의 일대일 매핑만 지원
- 교사 모델이 더 많은 어텐션 헤드를 가진 경우 여분의 헤드 정보는 손실됨
- 어텐션 헤드 간의 상관관계를 활용하지 못함
제안하는 방법:
- 어텐션 맵 평탄화: 각 어텐션 맵의 행을 연결하여 벡터 형태로 변환
- 가중 매핑 방식: 교사의 어텐션 맵이 여러 학생 어텐션 맵에 가중치 방식으로 매핑됨
- 코사인 유사도 기반 가중치: 평탄화된 교사-학생 어텐션 맵 간의 코사인 유사도를 바탕으로 가중치 결정
Loss Function 구성:
출력 일치 손실: 교사와 학생 모델의 최종 출력 간 차이를 최소화
어텐션 맵 정렬 손실: 교사의 어텐션 맵과 학생 어텐션 헤드에서 생성된 맵의 가중 합 간 거리를 최소화장졈:
- 효율적인 지식 전달: 교사 모델보다 적은 어텐션 헤드를 가진 학생 모델에도 효과적으로 지식 전달 가능
- 멀티모달 사전학습 보완: 실험 결과, AMAD는 교사 모델에 멀티모달 사전 훈련이 부족한 경우에도 그 부족분을 상당 부분 보완 가능
- 어텐션 헤드 간 상관관계 활용: 교사 모델의 여러 어텐션 맵이 가진 상관관계를 활용하여 학생 모델에 효율적으로 지식을 압축
이 새로운 방법을 두 가지 비전-언어 모델에 적용하여 평가했습니다. 이 모델들은 이미지와 텍스트를 동일한 벡터 공간에 매핑하며, 시각적 질문-답변, 이미지 캡셔닝, 이미지 컨텍스트 기반 번역 작업에 대해 미세 조정되었습니다. 평가 결과, 제안된 방식이 기존의 최신 기법들보다 모든 영역에서 더 우수한 성능을 보였습니다.
KNOWLEDGE DISTILLATION USING FRONTIER OPEN-SOURCE LLMS: GENERALIZABILITY AND THE ROLE OF SYNTHETIC DATA
Llama-3.1-Instruct-405B와 같은 선도적인 오픈소스 대규모 언어 모델(LLM)은 텍스트 생성, 질문 답변 및 다양한 자연어 이해 작업을 수행하는 데 매우 뛰어난 능력을 보입니다. 그러나 이러한 모델들은 작은 LLM에 비해 추론 비용과 지연 시간이 더 높습니다. 지식 증류는 이러한 대형 교사 모델의 출력을 활용하여 더 작은 학생 모델을 훈련시키는 방법을 제공하며, 이를 통해 비슷한 정확도를 유지하면서도 더 낮은 비용과 지연 시간으로 추론을 수행할 수 있습니다.
-> 해당 연구는 Llama-3.1-405B-Instruct 교사 모델과 더 작은 Llama-3.1-8B-Instruct 및 Llama-3.1-70B-Instruct 학생 모델을 사용한 증류의 효과를 조사했습니다.
본 연구의 contribution은 다음과 같습니다:
- 다양한 작업과 데이터셋에서의 일반화 가능성 평가
- Llama-3.1-405B(교사)에서 Llama-3.1-8B 및 70B(학생) 모델로의 지식 증류 효과 검증
- 여러 다른 작업과 데이터셋에서 일관된 성능 향상 확인
- 합성 데이터의 중요성 입증
- 증류 과정에서 합성 데이터 사용 시 8B 및 70B 모델 정확도 크게 향상
- 추론 체인과 함께 사용할 경우, 일부 데이터셋에서는 405B 모델의 제로샷 정확도와 비슷하거나 능가하는 성능 달성
- Task-specific Prompt Engineering을 활용하여 Distillation 성능을 극대화 가능
- 표준 미세 조정만으로 추론 능력 전달
- 특별한 손실 함수 없이도 표준 미세 조정으로 405B의 추론 능력을 8B 및 70B 모델에 내재화 가능
- 결과적으로 비용과 지연 시간이 크게 절감된 효율적인 학생 모델 추론 구현
- 철저한 평가 방법론 제시
- 지식 증류 평가의 일반적 함정 지적
- 인간 평가, LLM 평가, 전통적 정확도 벤치마크를 포함한 다각적 평가 방법 제안
- 작업별로 특화된 평가의 중요성 강조
방법론 Soft Label 사용 여부 추가 Loss 적용 여부 Task-specific Prompt 사용 여부 기존 Resopne-based KD Softmax 확률값 사용 KL Divergence Loss 추가 X 일반 데이터 활용 논문에서 제안한 방법 X Hard Label 사용 X 기존 CE loss 유지 O Prompt Engineering으로 Task 별 최적화 - 논문에서는 기존 Knowledge Distillation에서 사용하는 KL Divergence 기반 Loss를 사용하지 않고, 일반적인 Fine-tuning Loss를 그대로 적용
- 즉, Student 모델이 Teacher 모델의 출력을 정답(ground truth)으로 보고, 기존 Cross-Entropy Loss를 그대로 적용함
Q. Softmax 확률값(Sofrt Label)을 사용하지 않은 이유는?
- 모델 간 아키텍처 차이 고려
- 일반적으로 Knowledge Distillation에서는 Teacher의 Softmax 출력을 Student 모델이 학습하지만,
- Teacher 모델과 Student 모델의 구조(파라미터 수, 아키텍처)가 다를 경우 Soft Label을 학습하는 것이 비효율적
- 따라서, Hard Label만을 사용하여 Distillation을 간소화
- Fine-tuning API를 활용하기 쉽게 설계
- 일반적인 Fine-tuning API에서는 Loss 함수를 커스텀하기 어렵기 때문에,
- 기존 Cross-Entropy Loss를 유지하면서도 Distillation을 적용할 수 있도록 설계
단순한 Loss로도 합성 데이터의 품질만 좋다면 Distillation이 가능하다.
Reference
- Knowledge distillation method for better vision-language models
- Knowledge Distillation Using Frontier Open-Source LLMs: Generalizability and the Role of Synthetic Data
- Amazon Bedrock Model Distillation
- Amazon Bedrock Model Distillation Guide - JSONL training data available in Amazon S3 bucket
- KNOWLEDGE DISTILLATION USING FRONTIER OPEN-SOURCE
LLMS: GENERALIZABILITY AND THE ROLE OF SYNTHETIC
DATA
'Dev & Carrer > Cloud & AWS Architecture' 카테고리의 다른 글
Amazon Bedrock AgentCore의 모든 것: 기본 개념부터 최신 Policy & Evaluation 기능까지 (0) 2026.03.01